don’t decay the learning rate
|
A arXiv:171100489v2 [csLG] 24 Feb 2018
When one decays the learning rate one simultaneously decays the scale of random fluctu-ations g in the SGD dynamics Decaying the learning rate is simulated annealing We propose an alternative procedure; instead of decaying the learning rate we increase the batch size during training |
|
How to decay your learning rate
Complex learning rate schedules have become an integral part of deep learning We find empirically that common fine-tuned schedules decay the learn-ing rate after the weight norm bounces This leads to the proposal of ABEL: an automatic scheduler which decays the learning rate by keeping track of the weight norm ABEL’s performance matches that of |
Does Abel decay the learning rate after the weight norm bounces?
We find empirically that common fine-tuned schedules decay the learn-ing rate after the weight norm bounces. This leads to the proposal of ABEL: an automatic scheduler which decays the learning rate by keeping track of the weight norm. ABEL’s performance matches that of tuned schedules and is more robust with respect to its parameters.
Do complex learning rate schedules decay after weight norm bounces?
Complex learning rate schedules have become an integral part of deep learning. We find empirically that common fine-tuned schedules decay the learn-ing rate after the weight norm bounces. This leads to the proposal of ABEL: an automatic scheduler which decays the learning rate by keeping track of the weight norm.
What happens if a learning rate is decayed?
When one decays the learning rate, one simultaneously decays the scale of random fluctu-ations g in the SGD dynamics. Decaying the learning rate is simulated annealing. We propose an alternative procedure; instead of decaying the learning rate, we increase the batch size during training.
Can a learning curve be decayed?
It is common practice to decay the learning rate. Here we show one can usually obtain the same learning curve on both training and test sets by instead increasing the batch size during training. This procedure is successful for stochastic gradient descent (SGD), SGD with momentum, Nesterov momentum, and Adam.
Abstract
Complex learning rate schedules have become an integral part of deep learning. We find empirically that common fine-tuned schedules decay the learn-ing rate after the weight norm bounces. This leads to the proposal of ABEL: an automatic scheduler which decays the learning rate by keeping track of the weight norm. ABEL’s performance matches that of
Comparison of ABEL with other schedules
It is very natural to compare ABEL with step-wise decay. Step-wise decay is complicated to use in new settings be-cause on top of the base learning rate and the decay factor, one has to determine when to decay the learning rate. ABEL, takes care of the ‘when’ automatically without hurting per-formance. Because when to decay depends strongly on the
4. Understanding weight norm bouncing
In this section, we will pursue some first steps towards understanding the mechanism behind the phenomena that we found empirically in the previous sections. arxiv.org
2 gt wt + O( 2 ) (1)
be beneficial. In other setups, training with a constant learn-ing rate and decay it at the end of training should not hurt performance and might be a preferable, simpler method. ABEL’s hyperparameters. The main hyperparameters of ABEL are the base learning rate and decay factor: while our schedule is not hyperparameter free, ABEL is more robust th
What is the behaviour of the layerwise weight norm?
As discussed previously and in the SM B.2, most layers exhibit the same pattern as the total weight norm. Understanding the source of the generalization advan-tage of learning rate schedules. It would be nice to un-derstand if the bouncing of the weight norm is a proxy for some other phenomena. While we have tried tracking other simple quantities,
Acknowledgments
The authors would like to thank Anders Andreassen, Yasaman Bahri, Ethan Dyer, Orhan Firat, Pierre Foret, Guy Gur-Ari, Jaehoon Lee, Behnam Neyshabur and Vinay Ra-masesh for useful discussions. arxiv.org
")
Learning Rate Decay (C2W2L09)

Momentum and Learning Rate Decay

Learning Rate in a Neural Network explained
|
DONT DECAY THE LEARNING RATE INCREASE THE BATCH SIZE
DON'T DECAY THE LEARNING RATE. INCREASE THE BATCH SIZE. Samuel L. Smith tal evidence that the empirical benefits of decaying learning rates in deep learning ... |
|
Dont Decay the Learning Rate Increase the Batch Size
Feb 24 2018 We train ResNet-50 on ImageNet to 76.1% validation accuracy in under 30 minutes. 1 INTRODUCTION. Stochastic gradient descent (SGD) remains the ... |
|
Reconciling Modern Deep Learning with Traditional Optimization
This yields: (a) A new “intrinsic learning rate” parameter that is the product of the normal learning rate 7 and weight decay factor λ. Analysis of the. SDE |
|
The large learning rate phase of deep learning: the catapult
Mar 4 2020 Don't Decay the Learning Rate |
|
Dont Decay the Learning Rate Increase the Batch Size
Samuel L. Smith Pieter-Jan Kindermans |
|
Towards Explaining the Regularization Effect of Initial Large
Don't decay the learning rate increase the batch size. arXiv preprint arXiv:1711.00489 |
|
Improving Gradient Descent-based Optimization
Don't decay the learning rate increase the batch size. arXiv preprint arXiv:1711.00489. (a). (b). Figure 6: Inception-ResNet-V2 |
|
Maximal Initial Learning Rates in Deep ReLU Networks
-J. Ying |
|
CSC 2541: Neural Net Training Dynamics - Lecture 5 - Adaptive
Feb 11 2021 Don't you want to know what internal covariate shift is? Batch. Norm has ... Additionally |
|
Chapter 5 Adaptive Gradient Methods Normalization
https://www.cs.toronto.edu/~rgrosse/courses/csc2541_2021/readings/L05_normalization.pdf |
|
DONT DECAY THE LEARNING RATE INCREASE THE BATCH SIZE
We train ResNet-50 on ImageNet to 76.1% validation accuracy in under 30 minutes. 1 INTRODUCTION. Stochastic gradient descent (SGD) remains the dominant |
|
Dont Decay the Learning Rate Increase the Batch Size
Don't Decay the Learning Rate. Increase the Batch Size. Samuel L. Smith |
|
Learning-Rate Annealing Methods for Deep Neural Networks
22 août 2021 The popular decay methods of the learning rate are the step ... Ying C.; Le |
|
Dont Decay the Learning Rate Increase the Batch Size
24 févr. 2018 (2017) already observed this scaling rule empirically and exploited it to train ResNet-50 to 76.3% ImageNet validation accuracy in one hour. |
|
NVIDIA MGPU DLI: Optimization Strategies
Increasing the batch size instead of learning rate decay. Smith |
| Improving Gradient Descent-based Optimization |
|
Recitation 3.2
Step Decay: Reduce the learning rate by a factor every few epochs. Typical values Too Small: don't get rid of the local optima. • Choose of batch size. |
|
Scaling Deep Learning Training
Don't decay the learning-rate increase batch-size. Smith et al. arXiv:1711.00489 use batch-size scaling to train on ImageNet in 2500 parameter updates. |
|
The Limit of the Batch Size
15 juin 2020 Don't decay the learning rate increase the batch size. arXiv preprint arXiv:1711.00489 |
|
Large Batch Training
Don't Decay the Learning Rate Increase the Batch Size |
|
Dont decay the leaning rate
DON'T DECAY THE LEARNING RATE To maximize the test set accuracy (at constant learning rate) Existed problem: when one decays the learning rate, |
|
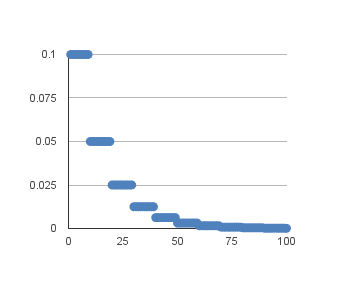
The Step Decay Schedule: A Near Optimal, Geometrically - NeurIPS
any polynomially decaying learning rate scheme is highly sub-optimal compared shows that Step Decay schedules, which cut the learning rate by a constant factor methods that tend to discard hyper-parameters which don't perform well at |
|
Towards Explaining the Regularization Effect of Initial Large
Abstract Stochastic gradient descent with a large initial learning rate is widely used for weight decay, no data augmen- tation Don't decay the learning rate |
|
Lecture 8: Optimization
can it be advantageous to decay the learning rate over time? • Be aware of various In practice, we don't compute the gradient on a single example, but |
|
Control Batch Size and Learning Rate to Generalize Well - NeurIPS
training strategy that we should control the ratio of batch size to learning rate not too large to achieve a Don't decay the learning rate, increase the batch size |
|
No More Pesky Learning Rates - Proceedings of Machine Learning
the learning rate (or step size) for each model and each problem, as fixed or decaying learning rates (full lines): any fixed learning rate limits the precision to which the optimum can Variants are marked in bold if they don't differ statistically |








![PDF] Combining learning rate decay and weight decay with](https://d3i71xaburhd42.cloudfront.net/9f2fb6899e046e1f42792ba6f22b0877149062eb/17-Figure15-1.png "PDF] Combining learning rate decay and weight decay with")
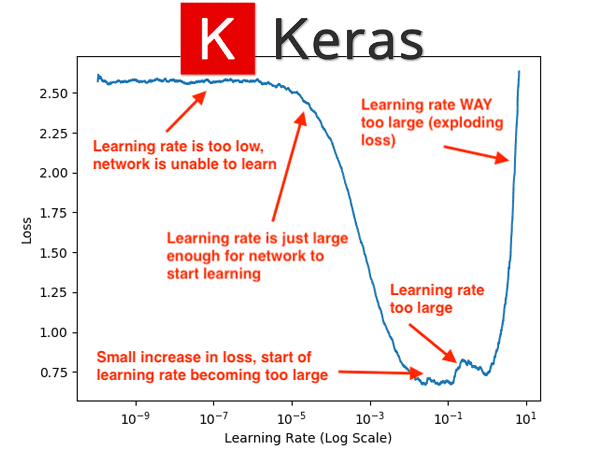
![PDF] A disciplined approach to neural network hyper-parameters](https://pyimagesearch.com/wp-content/uploads/2019/07/keras_learning_rates_header.png "PDF] A disciplined approach to neural network hyper-parameters")








![PDF] The Step Decay Schedule: A Near Optimal Geometrically](https://storage.googleapis.com/kaggle-forum-message-attachments/inbox/642483/73906ba9af381a9e4a5bc0e7ca764896/pre_trained.png "PDF] The Step Decay Schedule: A Near Optimal Geometrically")

 PACL: Piecewise Arc Cotangent Decay Learning Rate for Deep")




 Forget the Learning Rate Decay Loss")
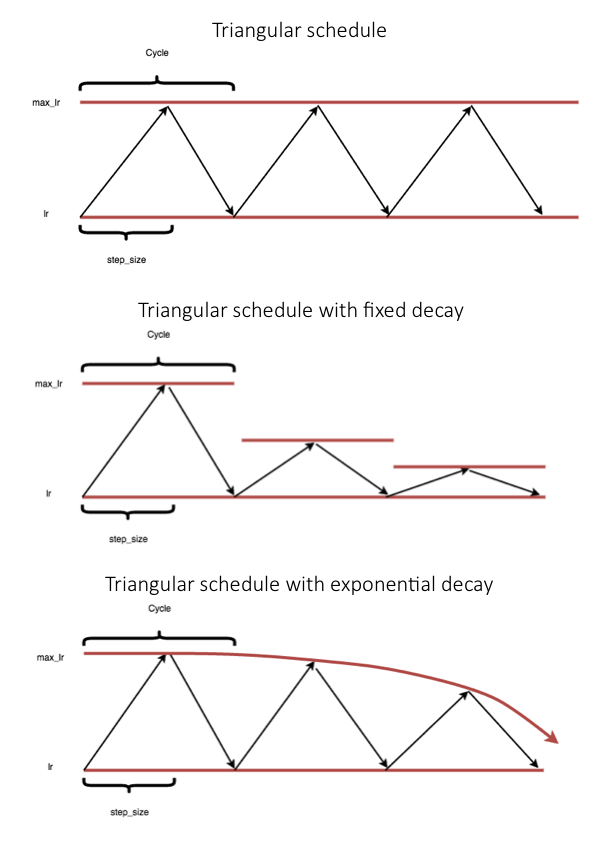
![PDF] The Step Decay Schedule: A Near Optimal Geometrically](https://pyimagesearch.com/wp-content/uploads/2019/07/keras_clr_triangular.png "PDF] The Step Decay Schedule: A Near Optimal Geometrically")

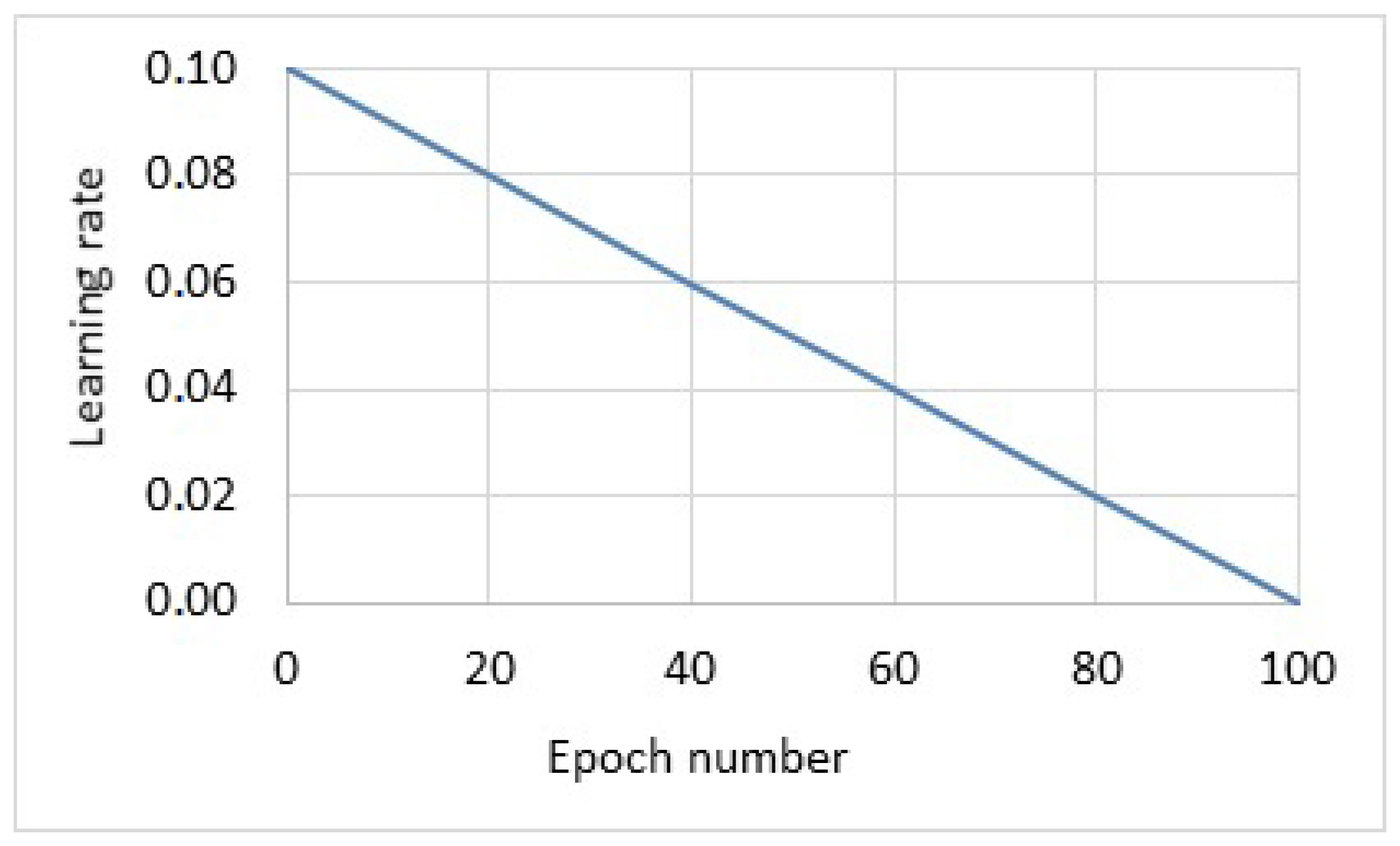

![PDF] The Step Decay Schedule: A Near Optimal Geometrically](https://miro.medium.com/max/408/1*VaHVbnxikt6KD5-etumSSw.png "PDF] The Step Decay Schedule: A Near Optimal Geometrically")
![PDF] The Step Decay Schedule: A Near Optimal Geometrically](https://miro.medium.com/max/2212/1*EFOPzKDz4f-SwErP_X9ixw.png "PDF] The Step Decay Schedule: A Near Optimal Geometrically")